Fabric Data Days: de stad van morgen begint met data
De uitdaging. Van dataset naar verhaal
Fabric Data Days is een periode van vijftig dagen waarin leren, delen en experimenteren centraal staan binnen de Fabric community. Voor mij voelde dit als het juiste moment om mezelf uit te dagen. Ik werk inmiddels bijna twee jaar met Microsoft Fabric en wilde mijn kennis eens op een andere manier inzetten dan ik dagelijks doe
Daarom besloot ik mee te doen aan de Notebook Contest Cities of Tomorrow. De opdracht was duidelijk. Neem een onbekende dataset en vertaal die naar een verhaal dat niet alleen technisch klopt, maar ook begrijpelijk en interessant is. Data moest niet alleen correct zijn, maar ook gaan leven.
De dataset. Wat zit er eigenlijk in
Voor deze challenge gebruikte ik een dataset van Kaggle over duurzame stedelijke ontwikkeling. De dataset bevat 3476 unieke steden, gescoord op verschillende factoren die samen iets zeggen over leefbaarheid. Denk aan groene ruimte, hernieuwbare energie, openbaar vervoer, uitstoot, criminaliteit en rampenrisico.
Na het downloaden van de data en het laden in een pandas DataFrame begon het bekende werk. Kolommen hernoemen, basisstatistieken bekijken en waarden herschalen zodat ze beter te interpreteren zijn. Noodzakelijke stappen om een goed beeld te krijgen van waar je mee werkt.
 Eerste verkenning van de dataset met meer dan drieduizend steden
Eerste verkenning van de dataset met meer dan drieduizend steden
Eerst begrijpen. Hoe is de data verdeeld
Voordat je relaties gaat onderzoeken, is het belangrijk om te begrijpen hoe de data is opgebouwd. Daarom begon ik met het bekijken van de verdeling van de belangrijkste variabelen.
De Livability Index viel daarbij direct op. Deze score laat een bijna normale verdeling zien en fungeert als de eindscore voor een stad. Dat maakt het een logische doelvariabele voor verdere analyses en voor het bouwen van een regressiemodel.

De Livability Index als centrale maat voor stedelijke leefbaarheid
Relaties tussen factoren
Met een goed beeld van de verdelingen was het tijd om te kijken naar relaties tussen de verschillende factoren. Door correlaties te berekenen werd snel duidelijk welke variabelen elkaar versterken en welke elkaar juist tegenwerken.
In de correlatiematrix zie je zowel sterke positieve als negatieve verbanden. Dit soort overzichten zijn ideaal om snel te begrijpen welke factoren echt invloed hebben op leefbaarheid.

Overzicht van samenhang tussen duurzaamheidsfactoren
Wat helpt steden vooruit en wat niet
Twee relaties sprongen er duidelijk uit. Groene ruimte heeft een sterke positieve relatie met leefbaarheid, terwijl criminaliteit juist een duidelijk negatieve invloed heeft. Dit zijn inzichten die logisch klinken, maar veel krachtiger worden als je ze visueel onderbouwt.
Met regressieplots worden deze verbanden direct zichtbaar en makkelijk te interpreteren.
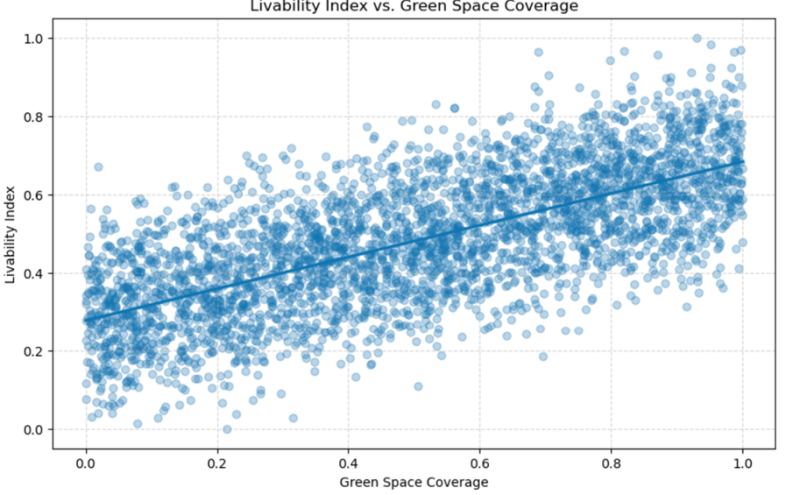 Meer groen hangt duidelijk samen met hogere leefbaarheid
Meer groen hangt duidelijk samen met hogere leefbaarheid

Hogere criminaliteit drukt de leefbaarheid van steden
Wanneer factoren samenkomen
Sommige effecten zie je pas goed wanneer je meerdere factoren tegelijk bekijkt. Met scatterplots kun je een extra dimensie toevoegen door kleur of grootte te gebruiken.
Een voorbeeld dat mij persoonlijk erg aansprak laat zien dat een lage uitstoot niet alles oplost. Zelfs met een lage carbon footprint kan een hoog rampenrisico de leefbaarheid sterk verlagen. De gebruikte kleurverdeling maakt dit effect in een oogopslag duidelijk.
 Hoog rampenrisico heeft een sterk negatief effect, zelfs bij lage uitstoot
Hoog rampenrisico heeft een sterk negatief effect, zelfs bij lage uitstoot
Van inzicht naar voorspellen
Na het verkennen van patronen wilde ik een stap verder gaan. Kunnen we leefbaarheid ook voorspellen. Hiervoor bouwde ik een regressiemodel met onder andere groene ruimte, hernieuwbare energie, openbaar vervoer, uitstoot, criminaliteit en rampenrisico.
De data splitste ik in een trainingsdeel en een testdeel. Als model koos ik voor een Random Forest Regressor. Een ensemble van beslisbomen die samen tot een voorspelling komen.
Het resultaat was beter dan ik vooraf had verwacht. Het model verklaarde 95.5 procent van de variatie in de data en had een zeer lage foutmarge. Dat gaf vertrouwen dat de gevonden patronen ook echt betekenisvol zijn.
Verschillen tussen soorten steden
Door steden in te delen in verschillende ontwikkelniveaus werd het beeld nog scherper. Foundational, developing en thriving cities laten duidelijke verschillen zien in hoe factoren zich ontwikkelen.
Zo groeit de hoeveelheid groene ruimte consistent mee met het ontwikkelniveau van een stad. Dit soort segmentatie helpt om beleid en investeringen gerichter te benaderen.
De toekomst is onzeker
Als laatste stap wilde ik laten zien dat leefbaarheid geen vast gegeven is. Met een Monte Carlo simulatie heb ik tienduizend mogelijke toekomstscenario’s doorgerekend. Elke simulatie combineert factoren zoals groen, energie, vervoer, uitstoot, criminaliteit en rampenrisico op een andere manier.
De uitkomsten laten een brede spreiding zien. Gemiddeld ligt de leefbaarheid rond het wereldwijde gemiddelde, maar afhankelijk van keuzes kan een stad sterk verbeteren of juist achteruitgaan.

Leefbaarheid als resultaat van keuzes en onzekerheid
De belangrijkste conclusie
De stad van morgen bouw je niet op slogans of goede bedoelingen. Je bouwt haar op data gedreven keuzes. Meer groen, minder uitstoot, slimme inzet van energie en voorbereiding op risico’s maken aantoonbaar verschil.
Leefbaarheid is geen vast punt, maar een spectrum. En nu weten we welke knoppen er echt toe doen.
Wie alle analyses, visualisaties en code wil bekijken, kan mijn volledige notebook vinden op GitHub
Tot slot
Deze challenge herinnerde me eraan hoe waardevol het is om buiten je dagelijkse routine te werken. Data science is mijn achtergrond, maar zo diep analyseren en modelleren doe ik niet elke dag. Juist daarom was dit leerzaam en leuk.
Misschien moet ik dit vaker doen!