Blogs
Blogpost
/ 25-6-2025
Blijf voorbereid op verandering: hoe we Azure-omgevingen verbeteren met het Well-Architected Framework
Azure verandert snel en als Managed klant hoef je dat niet alleen bij te houden. In dit bericht deelt Robert van Dijk hoe Wortell jou actief voorberei...
 Ga naar Blijf voorbereid op verandering: hoe we Azure-omgevingen verbeteren met het Well-Architected Framework
Ga naar Blijf voorbereid op verandering: hoe we Azure-omgevingen verbeteren met het Well-Architected Framework
Blogpost
/ 24-6-2025
Even voorstellen Peter Klapwijk - Senior Modern Workplace Consultant
Een nieuw gezicht bij Managed Services van Wortell namelijk; Peter Klapwijk! Stel jezelf een voor Peter...
 Ga naar Even voorstellen Peter Klapwijk - Senior Modern Workplace Consultant
Ga naar Even voorstellen Peter Klapwijk - Senior Modern Workplace Consultant
Blogpost
/ 23-6-2025
Beter beleid met de cloud: zó helpt governance jouw organisatie vooruit
Beleid voeren op je IT-omgeving is belangrijker dan ooit. Toch ontbreekt het veel organisaties aan een heldere governance-aanpak. De gevolgen? Onbevei...
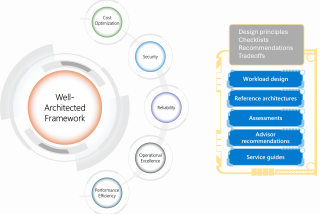 Ga naar Beter beleid met de cloud: zó helpt governance jouw organisatie vooruit
Ga naar Beter beleid met de cloud: zó helpt governance jouw organisatie vooruit
Blogpost
/ 23-6-2025
De verborgen kracht van Microsoft 365 voor de zorgsector: 3 elementen die de zorg méér ontzorgen
De druk op de zorgsector neemt toe. Door de dubbele vergrijzing, het toenemende personeelstekort en nieuwe wet- en regelgeving is efficiëntie bel...
 Ga naar De verborgen kracht van Microsoft 365 voor de zorgsector: 3 elementen die de zorg méér ontzorgen
Ga naar De verborgen kracht van Microsoft 365 voor de zorgsector: 3 elementen die de zorg méér ontzorgen
Blogpost
/ 11-6-2025
Security integraal bekeken anno 2025: “Het wordt alleen maar méér
Cyberrisico’s, het dreigingslandschap, het aanvalsoppervlak, compliance, governance, adoptie en de mens als actieve actor in de verdedigingslini...
 Ga naar Security integraal bekeken anno 2025: “Het wordt alleen maar méér
Ga naar Security integraal bekeken anno 2025: “Het wordt alleen maar méér
Blogpost
/ 10-6-2025
Een digitale werkplek die wél werkt. Zonder gedoe, mét resultaat.
In veel organisaties is informatie verspreid over tientallen plekken. Dit zorgt voor frustratie, verlies van tijd en onduidelijkheid. In deze blog lee...
 Ga naar Een digitale werkplek die wél werkt. Zonder gedoe, mét resultaat.
Ga naar Een digitale werkplek die wél werkt. Zonder gedoe, mét resultaat.
Blogpost
/ 4-6-2025
Windows 11 mei-update (KB5058405) veroorzaakt bootproblemen op virtuele machines.
Updates zijn er om je omgeving veiliger te maken, maar soms vragen ze nét wat extra aandacht. Dat geldt ook voor de Windows 11 security update...
 Ga naar Windows 11 mei-update (KB5058405) veroorzaakt bootproblemen op virtuele machines.
Ga naar Windows 11 mei-update (KB5058405) veroorzaakt bootproblemen op virtuele machines.
Blogpost
/ 15-5-2025
Waarom je vandaag moet stoppen met zoeken naar een werkplekbeheerder
Elke dag verschijnen er nieuwe vacatures voor werkplekbeheerders. Soms intern, soms via aanbesteding. Maar steeds vaker horen we dezelfde vragen: &ldq...
Ga naar Waarom je vandaag moet stoppen met zoeken naar een werkplekbeheerder
Blogpost
/ 14-5-2025
Follow the Data: waar data stroomt, schuilt het risico
In 2025 is data overal: in e-mails, Teams-chats, SaaS-applicaties en AI-modellen. De centrale vraag voor organisaties is dan ook urgenter dan ooit: wa...
 Ga naar Follow the Data: waar data stroomt, schuilt het risico
Ga naar Follow the Data: waar data stroomt, schuilt het risico
Blogpost
/ 9-5-2025
Wat zet je vandaag op je intranet?
Inspiratie nodig voor je intranet? Ontdek 25+ actuele ideeën die zorgen voor meer betrokkenheid, relevantie én bereik onder medewerkers.
 Ga naar Wat zet je vandaag op je intranet?
Ga naar Wat zet je vandaag op je intranet?
Blogpost
/ 2-5-2025
Geopolitieke druk op technologiekeuzes? Microsoft komt met krachtige toezeggingen aan Europa
Tijdens ons recente webinar over geopolitieke verschuivingen en technologische strategieën bespraken we hoe de wereldwijde context steeds vaker i...
 Ga naar Geopolitieke druk op technologiekeuzes? Microsoft komt met krachtige toezeggingen aan Europa
Ga naar Geopolitieke druk op technologiekeuzes? Microsoft komt met krachtige toezeggingen aan Europa
Blogpost
/ 23-4-2025
Slim samenwerken via een AI-gedreven intranet
Ontdek hoe een AI-gedreven intranet samenwerking versnelt, informatie toegankelijk maakt en je organisatie slimmer laat werken.
 Ga naar Slim samenwerken via een AI-gedreven intranet
Ga naar Slim samenwerken via een AI-gedreven intranet
Blogpost
/ 22-4-2025
Een dag vol inspiratie, innovatie en verbinding
Ontdek de hoogtepunten van de Wortell Userday Work & Cloud 2025, waar experts als Ben Kuzey (Microsoft), Lourens Siderius, Robert van Dijk, Marcel...
 Ga naar Een dag vol inspiratie, innovatie en verbinding
Ga naar Een dag vol inspiratie, innovatie en verbinding
Blogpost
/ 17-4-2025
Versnellen met AI: hoe zet je AI écht slim in?
AI: voor velen is het inmiddels de heilige graal. Begrijpelijk, want je kan er ontzettend veel mee. Tegelijkertijd wil je juist daarom het kaf van het...
 Ga naar Versnellen met AI: hoe zet je AI écht slim in?
Ga naar Versnellen met AI: hoe zet je AI écht slim in?
Blogpost
/ 7-4-2025
Kies jij voor een virtuele werkplek? Dít zijn de voordelen!
Altijd en overal veilig werken? Ontdek hoe een virtuele werkplek zorgt voor continuïteit, rust en grip op je IT-beheer. Bekijk alle voordelen!
 Ga naar Kies jij voor een virtuele werkplek? Dít zijn de voordelen!
Ga naar Kies jij voor een virtuele werkplek? Dít zijn de voordelen!
Blogpost
/ 1-4-2025
Podcast
#1 Boardroom Bytes: Last-mile logistics & first-class innovatie bij Mileway
In de eerste aflevering van de nieuwe podcastserie Boardroom Bytes trapt Danny Burlage, CEO van Wortell, af met een inspirerend gesprek met...
 Ga naar #1 Boardroom Bytes: Last-mile logistics & first-class innovatie bij Mileway
Ga naar #1 Boardroom Bytes: Last-mile logistics & first-class innovatie bij Mileway
Blogpost
/ 1-4-2025
Slimmer werken in de zorg met Debble
Ontdek hoe het intranetplatform Debble zorgorganisaties helpt met efficiënte communicatie, kennisdeling en slimme integraties. Lees de highlights...
 Ga naar Slimmer werken in de zorg met Debble
Ga naar Slimmer werken in de zorg met Debble
Blogpost
/ 21-3-2025
Voorjaarsschoonmaak op je intranet: Ruim je content op!
Geef je intranet een frisse start met de voorjaarsschoonmaak! Ontdek hoe je met Debble Analytics en slim retentiebeleid je intranet up-to-date houdt e...
 Ga naar Voorjaarsschoonmaak op je intranet: Ruim je content op!
Ga naar Voorjaarsschoonmaak op je intranet: Ruim je content op!